
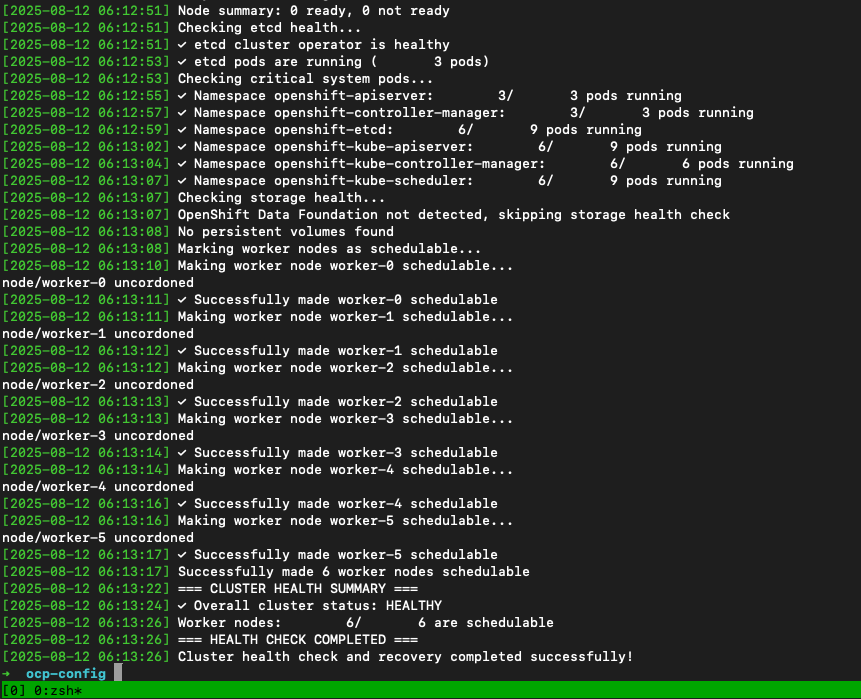
This script provides a comprehensive approach to verifying your OpenShift cluster health and ensures worker nodes are properly configured for scheduling after a graceful shutdown and restart. This script is tested against OpenShift Container Platform 4.18.x and 4.19.x.
Usage Instructions
- Save the script to a file (e.g.,
openshift-health-check.sh) - Make it executable:
chmod +x openshift-health-check.sh - Ensure you’re logged into your OpenShift cluster:
oc login - Run the script:
./openshift-health-check.sh
Key Features
Comprehensive Health Checks:
- Cluster connectivity and authentication
- Cluster version verification
- Cluster operators status
- Node readiness and availability
- etcd health monitoring
- Critical system pods verification
- Storage health (if OpenShift Data Foundation is installed)
Worker Node Management:
- Automatically identifies worker nodes with scheduling disabled
- Uses
oc adm uncordonto mark nodes as schedulable - Provides detailed feedback on each operation
Robust Error Handling:
- Checks for OpenShift CLI availability
- Validates cluster connectivity before proceeding
- Provides colored output for easy status identification
- Comprehensive logging with timestamps
Script Automation
To run this script automatically upon cluster boot, you can:
1. Add it to systemd (recommended for RHEL/Fedora/CentOS):
sudo cp openshift-health-check.sh /usr/local/bin/
sudo systemctl enable --now openshift-health-check.service2. Add to cron for periodic checks:
# Run every 5 minutes after boot
@reboot sleep 60 && /path/to/openshift-health-check.shScript
This script provides a comprehensive approach to verifying your OpenShift 4.19 cluster health and ensures worker nodes are properly configured for scheduling after a graceful shutdown and restart.
#!/bin/bash
# OpenShift 4.19 Cluster Health Check and Recovery Script
# This script checks cluster health and marks worker nodes as schedulable after cluster startup
set -e
# Colors for output
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
NC='\033[0m' # No Color
# Logging function
log() {
echo -e "${GREEN}[$(date '+%Y-%m-%d %H:%M:%S')]${NC} $1"
}
warning() {
echo -e "${YELLOW}[$(date '+%Y-%m-%d %H:%M:%S')] WARNING:${NC} $1"
}
error() {
echo -e "${RED}[$(date '+%Y-%m-%d %H:%M:%S')] ERROR:${NC} $1"
}
# Function to check if oc command is available
check_oc_command() {
if ! command -v oc &> /dev/null; then
error "OpenShift CLI (oc) is not installed or not in PATH"
exit 1
fi
log "OpenShift CLI found"
}
# Function to check cluster connectivity
check_cluster_connectivity() {
log "Checking cluster connectivity..."
if oc whoami &> /dev/null; then
log "Successfully connected to OpenShift cluster"
log "Current user: $(oc whoami)"
log "Current project: $(oc project -q)"
else
error "Cannot connect to OpenShift cluster. Please check your credentials and cluster status"
exit 1
fi
}
# Function to check cluster version
check_cluster_version() {
log "Checking cluster version..."
local version_info=$(oc get clusterversion -o jsonpath='{.items[0].status.desired.version}')
log "Cluster version: $version_info"
# Check if cluster version operator is available
local cv_status=$(oc get clusterversion -o jsonpath='{.items[0].status.conditions[?(@.type=="Available")].status}')
if [[ "$cv_status" == "True" ]]; then
log "✓ Cluster version operator is available"
else
warning "Cluster version operator may have issues"
fi
}
# Function to check cluster operators health
check_cluster_operators() {
log "Checking cluster operators health..."
# Get all cluster operators and their status
local operators_status=$(oc get clusteroperators --no-headers)
local total_operators=$(echo "$operators_status" | wc -l)
local healthy_operators=0
local degraded_operators=0
echo "$operators_status" | while read -r line; do
local name=$(echo "$line" | awk '{print $1}')
local available=$(echo "$line" | awk '{print $3}')
local progressing=$(echo "$line" | awk '{print $4}')
local degraded=$(echo "$line" | awk '{print $5}')
if [[ "$available" == "True" && "$degraded" == "False" ]]; then
echo "✓ $name: Healthy"
((healthy_operators++))
else
echo "✗ $name: Available=$available, Progressing=$progressing, Degraded=$degraded"
((degraded_operators++))
fi
done
log "Cluster operators summary: $healthy_operators healthy, $degraded_operators with issues"
}
# Function to check node status
check_node_status() {
log "Checking node status..."
# Check all nodes
local nodes_info=$(oc get nodes --no-headers)
local total_nodes=$(echo "$nodes_info" | wc -l)
local ready_nodes=0
local not_ready_nodes=0
echo "$nodes_info" | while read -r line; do
local name=$(echo "$line" | awk '{print $1}')
local status=$(echo "$line" | awk '{print $2}')
local roles=$(echo "$line" | awk '{print $3}')
if [[ "$status" == "Ready" ]]; then
echo "✓ $name ($roles): Ready"
((ready_nodes++))
elif [[ "$status" =~ "Ready,SchedulingDisabled" ]]; then
echo "⚠ $name ($roles): Ready but SchedulingDisabled"
((ready_nodes++))
else
echo "✗ $name ($roles): $status"
((not_ready_nodes++))
fi
done
log "Node summary: $ready_nodes ready, $not_ready_nodes not ready"
}
# Function to check etcd health
check_etcd_health() {
log "Checking etcd health..."
# Check etcd cluster operator
local etcd_status=$(oc get co etcd -o jsonpath='{.status.conditions[?(@.type=="Available")].status}' 2>/dev/null)
if [[ "$etcd_status" == "True" ]]; then
log "✓ etcd cluster operator is healthy"
else
warning "etcd cluster operator may have issues"
fi
# Check etcd pods
local etcd_pods=$(oc get pods -n openshift-etcd -l app=etcd --no-headers 2>/dev/null | wc -l)
if [[ $etcd_pods -gt 0 ]]; then
log "✓ etcd pods are running ($etcd_pods pods)"
else
warning "No etcd pods found or unable to check"
fi
}
# Function to mark worker nodes as schedulable
mark_workers_schedulable() {
log "Marking worker nodes as schedulable..."
# Get all worker nodes that are not schedulable
local unschedulable_workers=$(oc get nodes -l node-role.kubernetes.io/worker --no-headers | grep "SchedulingDisabled" | awk '{print $1}')
if [[ -z "$unschedulable_workers" ]]; then
log "All worker nodes are already schedulable"
return 0
fi
local count=0
for worker in $unschedulable_workers; do
log "Making worker node $worker schedulable..."
if oc adm uncordon "$worker"; then
log "✓ Successfully made $worker schedulable"
((count++))
else
error "Failed to make $worker schedulable"
fi
done
log "Successfully made $count worker nodes schedulable"
}
# Function to verify cluster pods are running
check_critical_pods() {
log "Checking critical system pods..."
# Check key namespaces for pod health
local namespaces=("openshift-apiserver" "openshift-controller-manager" "openshift-etcd" "openshift-kube-apiserver" "openshift-kube-controller-manager" "openshift-kube-scheduler")
for ns in "${namespaces[@]}"; do
local pod_count=$(oc get pods -n "$ns" --no-headers 2>/dev/null | wc -l)
local running_pods=$(oc get pods -n "$ns" --no-headers 2>/dev/null | grep "Running" | wc -l)
if [[ $pod_count -gt 0 ]]; then
log "✓ Namespace $ns: $running_pods/$pod_count pods running"
else
warning "No pods found in namespace $ns or unable to check"
fi
done
}
# Function to check storage health (if ODF is installed)
check_storage_health() {
log "Checking storage health..."
# Check if OpenShift Data Foundation is installed
if oc get csv -A | grep -q "odf-operator" 2>/dev/null; then
log "OpenShift Data Foundation detected, checking storage health..."
# Check ODF operator status
local odf_status=$(oc get csv -A -o jsonpath='{.items[?(@.metadata.name=="odf-operator.v*")].status.phase}' 2>/dev/null)
if [[ "$odf_status" == "Succeeded" ]]; then
log "✓ ODF operator is healthy"
else
warning "ODF operator status: $odf_status"
fi
else
log "OpenShift Data Foundation not detected, skipping storage health check"
fi
# Check persistent volumes
local pv_count=$(oc get pv --no-headers 2>/dev/null | wc -l)
if [[ $pv_count -gt 0 ]]; then
local available_pvs=$(oc get pv --no-headers 2>/dev/null | grep "Available" | wc -l)
local bound_pvs=$(oc get pv --no-headers 2>/dev/null | grep "Bound" | wc -l)
log "✓ Persistent Volumes: $available_pvs available, $bound_pvs bound"
else
log "No persistent volumes found"
fi
}
# Function to perform overall health summary
health_summary() {
log "=== CLUSTER HEALTH SUMMARY ==="
# Check overall cluster status
local cluster_available=$(oc get clusterversion -o jsonpath='{.items[0].status.conditions[?(@.type=="Available")].status}')
local cluster_progressing=$(oc get clusterversion -o jsonpath='{.items[0].status.conditions[?(@.type=="Progressing")].status}')
if [[ "$cluster_available" == "True" && "$cluster_progressing" == "False" ]]; then
log "✓ Overall cluster status: HEALTHY"
else
warning "Overall cluster status: Available=$cluster_available, Progressing=$cluster_progressing"
fi
# Display worker node schedulability status
local total_workers=$(oc get nodes -l node-role.kubernetes.io/worker --no-headers | wc -l)
local schedulable_workers=$(oc get nodes -l node-role.kubernetes.io/worker --no-headers | grep -v "SchedulingDisabled" | wc -l)
log "Worker nodes: $schedulable_workers/$total_workers are schedulable"
log "=== HEALTH CHECK COMPLETED ==="
}
# Main execution
main() {
log "Starting OpenShift 4.19 cluster health check and recovery..."
# Perform health checks
check_oc_command
check_cluster_connectivity
check_cluster_version
check_cluster_operators
check_node_status
check_etcd_health
check_critical_pods
check_storage_health
# Mark worker nodes as schedulable
mark_workers_schedulable
# Wait a moment for changes to take effect
sleep 5
# Final health summary
health_summary
log "Cluster health check and recovery completed successfully!"
}
# Execute main function
main "$@"