
I tested the following scripts on:-
- OpenShift Container Platform 4.19.9
- OpenShift Data Foundation (ODF) 4.19.3
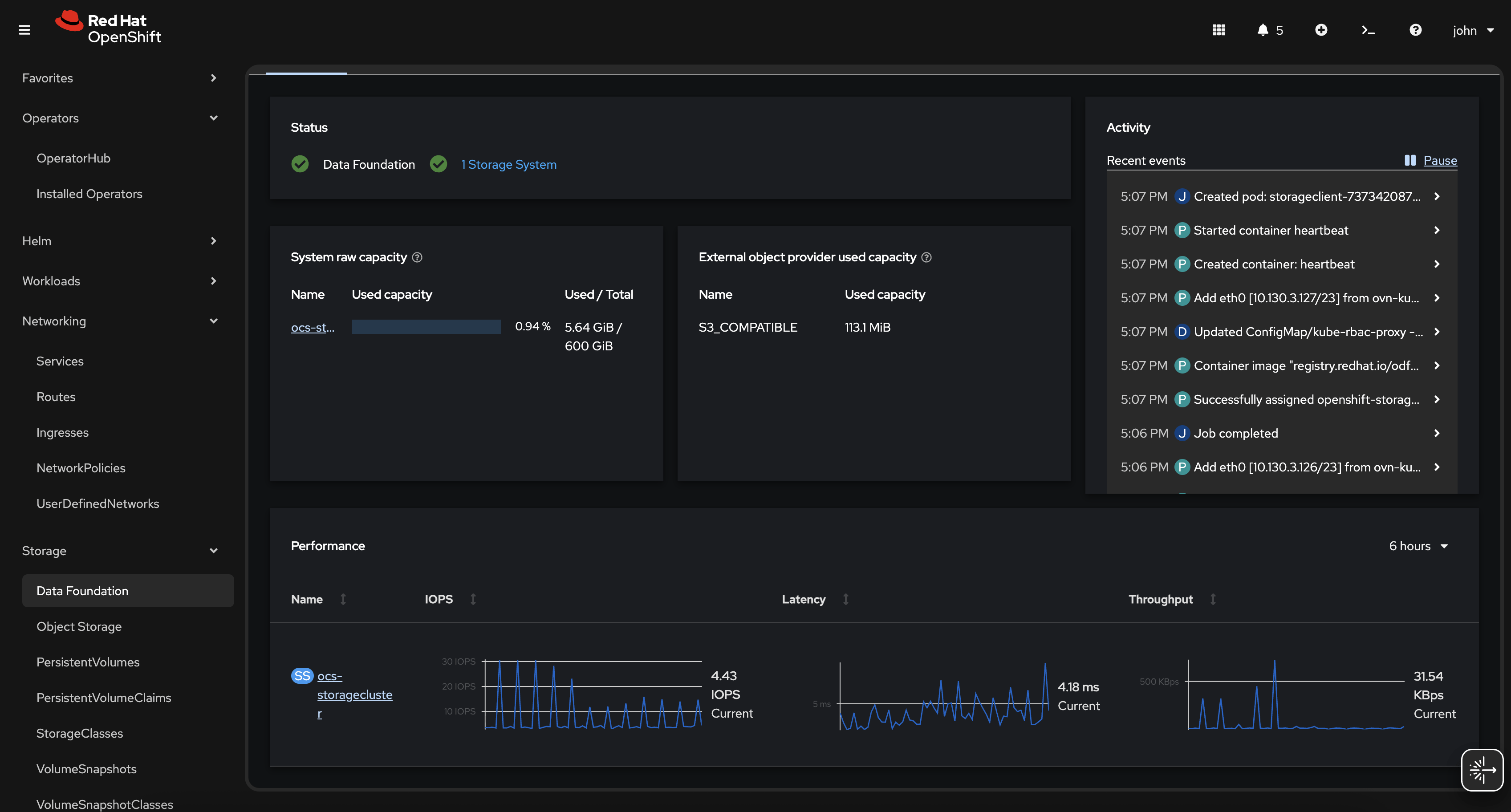
OpenShift Container Platform
Performance Monitoring
Watch actual usage and tune:
oc adm top pods -n openshift-storageNode overview (needs metrics):
oc adm top nodesRed Hat OpenShift Data Foundation
The following ceph outputs will give you more details than anything in ocp:
ceph df
ceph osd df tree
ceph statusODF – Utilization Consolidated View
This script provides a single consolidated view of the Ceph OSDs backing an OpenShift Data Foundation (ODF) storage cluster. It maps each deviceset PVC (the raw block volumes bound to Ceph OSD pods) to its OSD ID and shows the current OSD fullness percentage (OSD_UTIL_%) as reported by Ceph metrics in Prometheus.
Key features:
- Joins Kubernetes PVs → PVCs → Ceph OSD IDs.
- Queries Prometheus (
ceph_osd_stat_*metrics) for per-OSD utilization. - Produces a single table, sorted by
OSD_UTIL_%(descending), so the most utilized OSDs float to the top. - Works entirely through OpenShift / ODF APIs (no need for
cephCLI inside pods). - Includes a
DEBUG=1mode to show raw mapping and Prometheus lookups for troubleshooting.
This way, you can quickly spot which OSDs are the most full and confirm that each deviceset PVC is correctly tied back to its Ceph OSD ID.
Save the script as stitch.sh and make it executable. Run normally to get the utilization table.
./stitch.shAlternatively, run with debug mode if you want to verify how the script mapped PVCs to OSDs or Prometheus metrics.
DEBUG=1 ./stitch.sh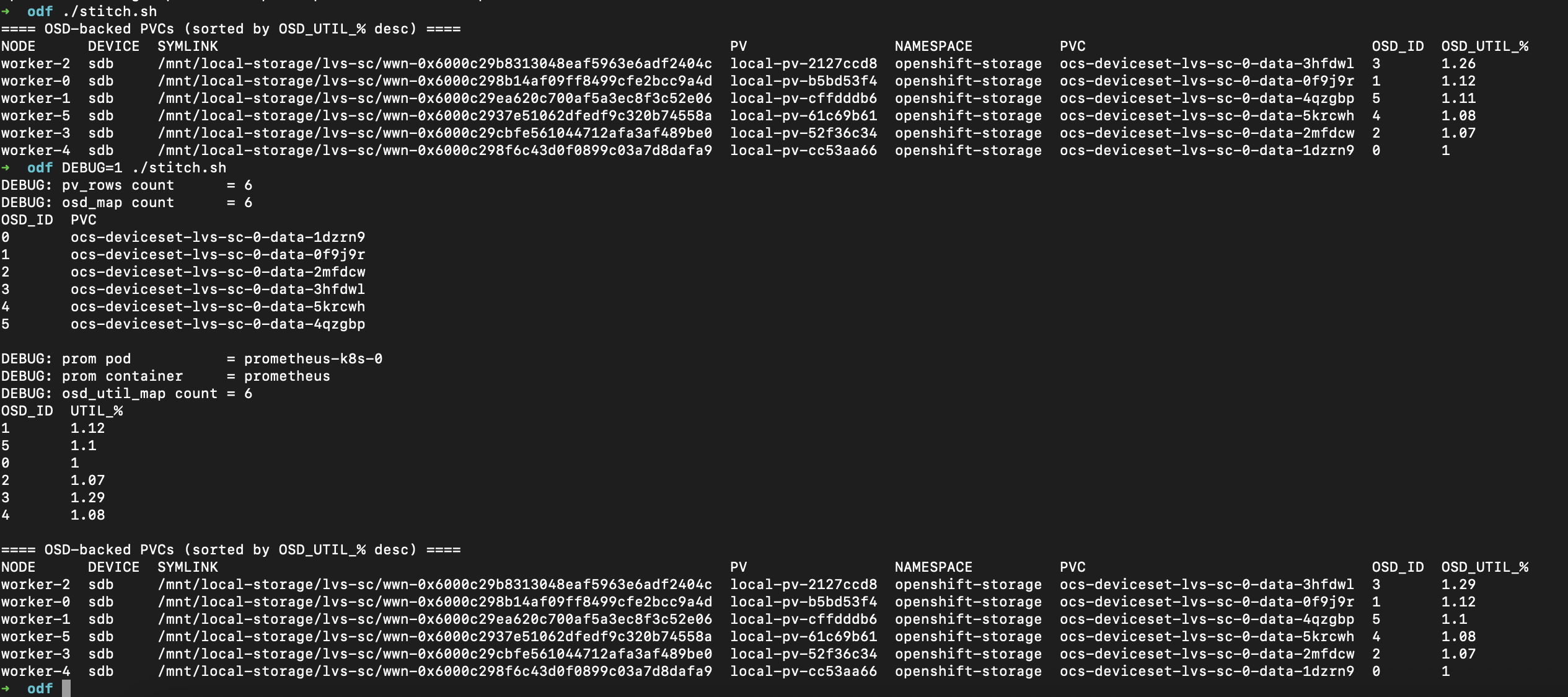
Full Script: stitch.sh
#!/usr/bin/env bash
#
# stitch.sh - Show Ceph OSD utilization mapped to ODF deviceset PVCs on OpenShift
#
# Purpose:
# This script joins Kubernetes PVs → PVCs → Ceph OSD IDs and displays
# per-OSD utilization (% full) as reported by Ceph metrics in Prometheus.
#
# Features:
# - Maps deviceset PVCs to their OSD IDs (via pod mounts/envs).
# - Queries Prometheus for ceph_osd_stat_* metrics (no ceph CLI needed).
# - Outputs a single table sorted by OSD_UTIL_% (descending).
# - DEBUG=1 mode prints raw mapping and metric lookups for troubleshooting.
#
# Usage:
# chmod +x stitch.sh
# ./stitch.sh # run normally
# DEBUG=1 ./stitch.sh # run with debug output
#
set -euo pipefail
have(){ command -v "$1" >/dev/null 2>&1; }
for b in oc jq column; do have "$b" || { echo "missing: $b" >&2; exit 1; }; done
DBG="${DEBUG:-0}"
# -------- helpers --------
pick_prom_pod() {
# try by label
local p
p="$(oc -n openshift-monitoring get pods -l app.kubernetes.io/name=prometheus -o name 2>/dev/null | head -n1 || true)"
if [[ -z "$p" ]]; then
# fallback by name prefix
p="$(oc -n openshift-monitoring get pods -o name 2>/dev/null | grep -E '^pod/prometheus-k8s-[0-9]+' | head -n1 || true)"
fi
echo "${p#pod/}"
}
pick_prom_container() {
# common names: 'prometheus' (container) or 'prometheus-k8s' depending on build
local pod="$1"
local c
c="$(oc -n openshift-monitoring get pod "$pod" -o json | jq -r '.spec.containers[].name' | grep -E '^(prometheus|prometheus-k8s)$' | head -n1 || true)"
# last resort: first container name
if [[ -z "$c" ]]; then
c="$(oc -n openshift-monitoring get pod "$pod" -o json | jq -r '.spec.containers[0].name' 2>/dev/null || echo "")"
fi
echo "$c"
}
# -------- 1) Local PV inventory (Local PVs bound to PVCs) --------
pv_rows="$(oc get pv -o json | jq '
[ .items[]
| select(.spec.claimRef != null)
| select(.spec.local.path != null)
| {
pv: .metadata.name,
node: (.metadata.labels["kubernetes.io/hostname"] // ""),
ns: (.spec.claimRef.namespace // ""),
pvc: (.spec.claimRef.name // ""),
symlink: (.spec.local.path // ""),
device: (.metadata.annotations["storage.openshift.com/device-name"] // "")
}
]')"
# -------- 2) OSD ↔ PVC mapping (scan containers + initContainers) --------
osd_json="$(oc -n openshift-storage get pods -l app=rook-ceph-osd -o json 2>/dev/null || echo '{"items":[]}')"
osd_map="$(jq '
[ .items[] as $pod
| ( $pod.metadata.labels["ceph-osd-id"]
// ( $pod.metadata.name | capture("rook-ceph-osd-(?<id>[0-9]+)-").id )) as $osd
| ( [ ($pod.spec.containers // [])[], ($pod.spec.initContainers // [])[] ]
| map(.volumeMounts // [])
| add
| map(select(.mountPath|test("^/var/lib/ceph/osd/")))
| map(.name)
| unique ) as $vm_names
| ( [ $pod.spec.volumes[]?
| select(.persistentVolumeClaim!=null and (.name as $n | $vm_names|index($n)))
| .persistentVolumeClaim.claimName ] | unique ) as $pvcs_from_mount
| ( [ ($pod.spec.containers // [])[], ($pod.spec.initContainers // [])[] ]
| map(.env // [])
| add
| map(select(.name=="ROOK_PVC") | .value)
| unique ) as $pvcs_from_env
| ( [ $pod.spec.volumes[]?
| select(.persistentVolumeClaim!=null)
| .persistentVolumeClaim.claimName ] | unique ) as $any_pvcs
| {
osd: $osd,
pvc: ( if ($pvcs_from_mount|length) > 0 then $pvcs_from_mount[0]
elif ($pvcs_from_env|length) > 0 then $pvcs_from_env[0]
elif ($any_pvcs|length) > 0 then $any_pvcs[0]
else null end )
}
| select(.osd!=null and .pvc!=null)
]' <<<"$osd_json")"
if [[ "$DBG" == "1" ]]; then
echo "DEBUG: pv_rows count = $(jq 'length' <<<"$pv_rows")"
echo "DEBUG: osd_map count = $(jq 'length' <<<"$osd_map")"
jq -r '["OSD_ID","PVC"], (.[] | [.osd,.pvc]) | @tsv' <<<"$osd_map" | column -t
echo
fi
# -------- 3) Ceph OSD utilization via Prometheus --------
PROM_POD="$(pick_prom_pod)"
PROM_CTR=""
if [[ -n "$PROM_POD" ]]; then
PROM_CTR="$(pick_prom_container "$PROM_POD")"
fi
if [[ "$DBG" == "1" ]]; then
echo "DEBUG: prom pod = ${PROM_POD:-<none>}"
echo "DEBUG: prom container = ${PROM_CTR:-<none>}"
fi
osd_util_json="$(
if [[ -n "${PROM_POD}" && -n "${PROM_CTR}" ]]; then
oc -n openshift-monitoring exec "$PROM_POD" -c "$PROM_CTR" -- \
curl -s --data-urlencode \
'query=100 * ceph_osd_stat_bytes_used{ceph_daemon=~"osd\\..+"} / ceph_osd_stat_bytes{ceph_daemon=~"osd\\..+"}' \
'http://localhost:9090/api/v1/query?' 2>/dev/null \
|| echo '{"data":{"result":[]}}'
else
echo '{"data":{"result":[]}}'
fi
)"
osd_util_map="$(jq '
(.data.result // [])
| map({
osd: ((.metric.ceph_daemon // "") | capture("osd\\.(?<id>[0-9]+)") | .id),
util: ((.value[1] | tonumber) | (.*100) | round / 100) # 2 decimals
})
| map(select(.osd != null and .osd != ""))
' <<<"$osd_util_json")"
if [[ "$DBG" == "1" ]]; then
echo "DEBUG: osd_util_map count = $(jq 'length' <<<"$osd_util_map")"
jq -r '["OSD_ID","UTIL_%"], (.[] | [.osd, (.util|tostring)]) | @tsv' <<<"$osd_util_map" | column -t
echo
fi
# -------- 4) Join & print single table (sort by OSD_UTIL_% desc; nulls last) --------
table="$(
jq -r \
--argjson pv "$pv_rows" \
--argjson osdmap "$osd_map" \
--argjson osdutil "$osd_util_map" '
# For each PV row, find osd_id by pvc (array join),
# then find util for that osd_id (array join).
[ $pv[]
| . as $r
| ( $osdmap | map(select(.pvc == $r.pvc)) | first ) as $m
| ( $osdutil | map(select(.osd == ($m.osd // ""))) | first ) as $u
| $r + {
osd_id: ($m.osd // ""),
osd_util:(if $u then $u.util else null end)
}
]
| sort_by( if .osd_util == null then -1 else .osd_util end ) | reverse
| (["NODE","DEVICE","SYMLINK","PV","NAMESPACE","PVC","OSD_ID","OSD_UTIL_%"],
( .[] | [
.node, .device, .symlink, .pv, .ns, .pvc,
(.osd_id|tostring),
(if .osd_util==null then "" else (.osd_util|tostring) end)
]))
| @tsv
' <<<"{}" | column -t
)"
echo "==== OSD-backed PVCs (sorted by OSD_UTIL_% desc) ===="
echo "$table"Find out which node/device backs each local PV, and which PVC is bound to it?
oc get pv \
-o 'custom-columns=HOST-NAME:.metadata.labels.kubernetes\.io/hostname,\
PVCNAME:.spec.claimRef.name,\
SYMLINK:.spec.local.path,\
DEV-NAME:.metadata.annotations.storage\.openshift\.com/device-name' \
| grep -v none
oc get pv: list PersistentVolumes.
-o custom-columns=...: print only selected fields.
HOST-NAME: node the local PV is pinned to (labelkubernetes.io/hostnameon the PV).PVCNAME: the bound PVC name (.spec.claimRef.name).SYMLINK: the local path used by the Local Storage operator (e.g.,/mnt/local-storage/...) from.spec.local.path.DEV-NAME: the underlying device name recorded by the Local Storage operator (annotationstorage.openshift.com/device-name), e.g.,/dev/nvme0n1.- Dots in field paths are escaped (
\.) because of the shell.
grep -v none: hide rows that containnone(often shows when a field is empty, also hides legitimate values containing “none”).
Show Ceph OSD pods → which PVC they mount
oc -n openshift-storage get pods -l app=rook-ceph-osd \
-o 'custom-columns=OSD_ID:.metadata.labels.ceph-osd-id,PVC:.spec.volumes[*].persistentVolumeClaim.claimName' \
--no-headers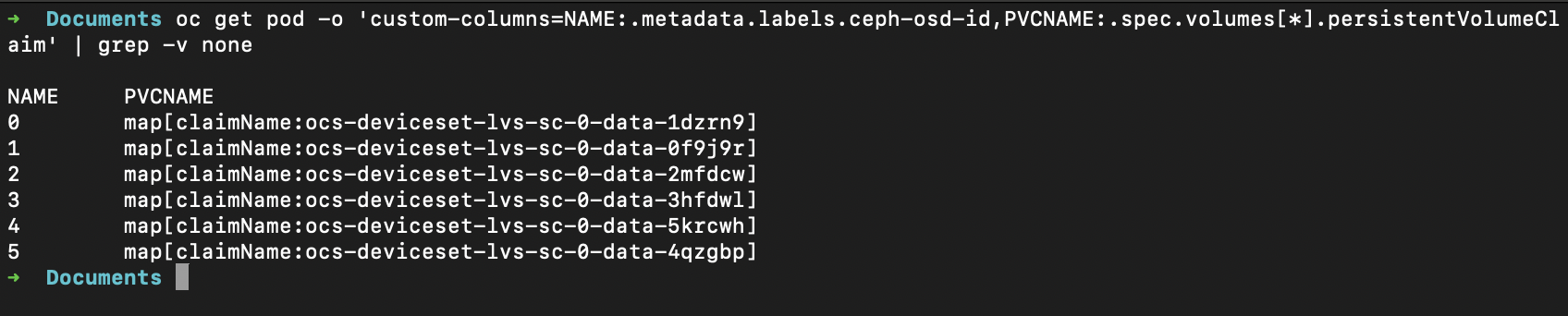
oc get pod: list pods (in the current namespace; for ODF OSDs this is usually-n openshift-storage).
NAME:.metadata.labels.ceph-osd-id: prints the Ceph OSD id from the pod label (e.g.,0,1, …).
(For non-OSD pods this label won’t exist.)
PVCNAME:.spec.volumes[*].persistentVolumeClaim: prints any PVCs mounted by each pod (usually the OSD data PVC).
grep -v none: suppress lines where either column is<none>.
Find out how much space a non-ODF PVC is using on a Node
This can also help with non odf pvcs:
oc -n openshift-monitoring exec -c prometheus prometheus-k8s-0 -- \
curl -s --data-urlencode \
"query=100*kubelet_volume_stats_used_bytes{persistentvolumeclaim=~\".*\"}/kubelet_volume_stats_capacity_bytes{persistentvolumeclaim=~\".*\"}" \
'http://localhost:9090/api/v1/query?' \
| jq '["NAMESPACE","NAME","USAGE(%)"],
(.data.result[] | [.metric.namespace,
.metric.persistentvolumeclaim,
(.value[1]|tonumber*100|round/100)])
| @tsv' -r \
| column -t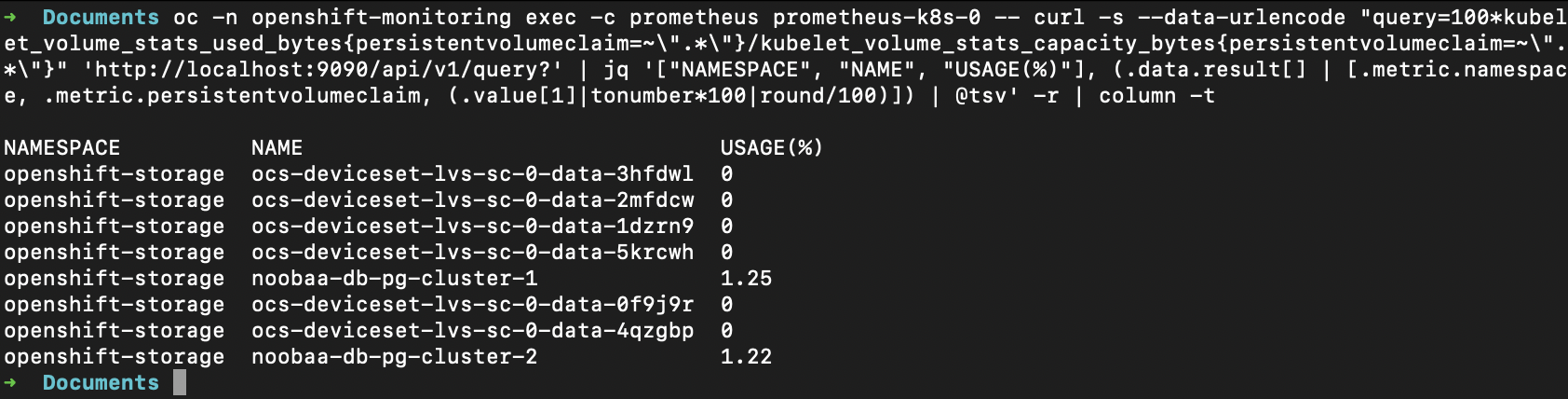
oc exec ... prometheus-k8s-0 -c prometheus: run a command inside the Prometheus pod.
curl ... /api/v1/query?: call Prometheus’s HTTP API onlocalhost:9090inside the pod.The PromQL expression:
kubelet_volume_stats_used_bytes{...}/kubelet_volume_stats_capacity_bytes{...}→ used / capacity per PVC from kubelet metrics.- multiplied by
100→ percent used. (The=~".*"selector just “match all PVCs”.)
jq: formats the JSON response into a TSV table with headers:
NAMESPACE,NAME(PVC),USAGE(%)(rounded to 2 decimals).
column -t: pretty-prints into aligned columns.
S3 client health-check script (test NooBa / ODF RGW)
What the script does? (Updated as of 7 Sept 2025)
- auto-detects the S3 endpoint from your current oc context
- optionally auto-loads NooBaa creds (AUTO_CREDS=1)
- Uploads a test file (
test-object.txt). - Lists the bucket contents.
- Downloads the file and verifies content matches.
- Cleans up the bucket and temporary files.
- chooses TLS in this order: system trust → default-ingress-cert → router-ca → live chain via openssl
For a super-quick test,
AUTO_CREDS=1 ./s3-client.sh
or
TLS_DEBUG=1 AUTO_CREDS=1 ./s3-client.sh
Full Script: noobaa-s3-health-check.sh
#!/usr/bin/env bash
set -euo pipefail
# Quick NooBaa S3 health check
# ======== Fill these in from `noobaa status` ========
AWS_ACCESS_KEY_ID="XXXXX"
AWS_SECRET_ACCESS_KEY="XXXXXX"
ENDPOINT="https://s3-openshift-storage.apps.xxx.xxx.xxx"
# ====================================================
export AWS_ACCESS_KEY_ID AWS_SECRET_ACCESS_KEY
# Try to fetch the OpenShift default ingress CA bundle
CA_FILE="$(mktemp)"
if oc get cm default-ingress-cert -n openshift-config-managed >/dev/null 2>&1; then
oc get cm default-ingress-cert -n openshift-config-managed \
-o jsonpath='{.data.ca-bundle\.crt}' > "$CA_FILE"
USE_CA="--ca-bundle $CA_FILE"
export AWS_CA_BUNDLE="$CA_FILE" # also works for awscli v2
else
echo "WARN: Could not find default-ingress-cert configmap; falling back to INSECURE mode unless you set one."
USE_CA=""
fi
# Allow override to skip TLS verification entirely (quick test only)
INSECURE="${INSECURE:-0}"
if [[ "$INSECURE" == "1" ]]; then
echo "⚠️ INSECURE=1 set: skipping TLS verification."
USE_CA="--no-verify-ssl"
fi
BUCKET="healthcheck-$(date +%s)"
OBJ="test-object.txt"
cleanup() {
set +e
aws $USE_CA --endpoint-url "$ENDPOINT" s3 rm "s3://$BUCKET/$OBJ" >/dev/null 2>&1
aws $USE_CA --endpoint-url "$ENDPOINT" s3 rb "s3://$BUCKET" --force >/dev/null 2>&1
rm -f "$OBJ" "dl-$OBJ" "$CA_FILE" 2>/dev/null
}
trap cleanup EXIT
echo "==> Creating bucket $BUCKET"
aws $USE_CA --endpoint-url "$ENDPOINT" s3 mb "s3://$BUCKET"
echo "==> Uploading object"
echo "hello from noobaa" > "$OBJ"
aws $USE_CA --endpoint-url "$ENDPOINT" s3 cp "$OBJ" "s3://$BUCKET/"
echo "==> Listing bucket"
aws $USE_CA --endpoint-url "$ENDPOINT" s3 ls "s3://$BUCKET/"
echo "==> Downloading object"
aws $USE_CA --endpoint-url "$ENDPOINT" s3 cp "s3://$BUCKET/$OBJ" "dl-$OBJ"
diff -q "$OBJ" "dl-$OBJ" && echo "✅ Content matches."
echo "==> Cleaning up"
# (handled by trap)
echo "==> Done!"
Monitor nooba-S3 Storage with OpenShift cronjob (minimal check HTTP 200)
Add the script to a cronjob to run periodically. This is a minimal example (just checks HTTP 200).
apiVersion: batch/v1
kind: CronJob
metadata:
name: noobaa-s3-healthcheck
namespace: openshift-storage
spec:
schedule: "*/15 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: s3-healthcheck
image: registry.redhat.io/openshift4/ose-cli:latest
command: ["/bin/bash", "-c"]
args:
- |
curl -k --fail https://s3-openshift-storage.apps.avengers.kubernetes.day || exit 1
restartPolicy: NeverMonitor nooba-S3 Storage with OpenShift cronjob (full check)
Here’s a ready-to-apply OpenShift CronJob that runs the full S3 health check inside the cluster, using the internal S3 service (https://s3.openshift-storage.svc:443) and trusting the injected service CA (so no TLS errors).
It creates:
- a Secret for your AWS-style keys
- a ConfigMap with the script
- a ConfigMap that gets the service CA injected automatically
- a CronJob (runs every 15 minutes; adjust as you like)
Apply in the namespace that hosts MCG/NooBaa (usually
openshift-storage):
oc apply -n openshift-storage -f noobaa-s3-health-cronjob.yamlScript below.
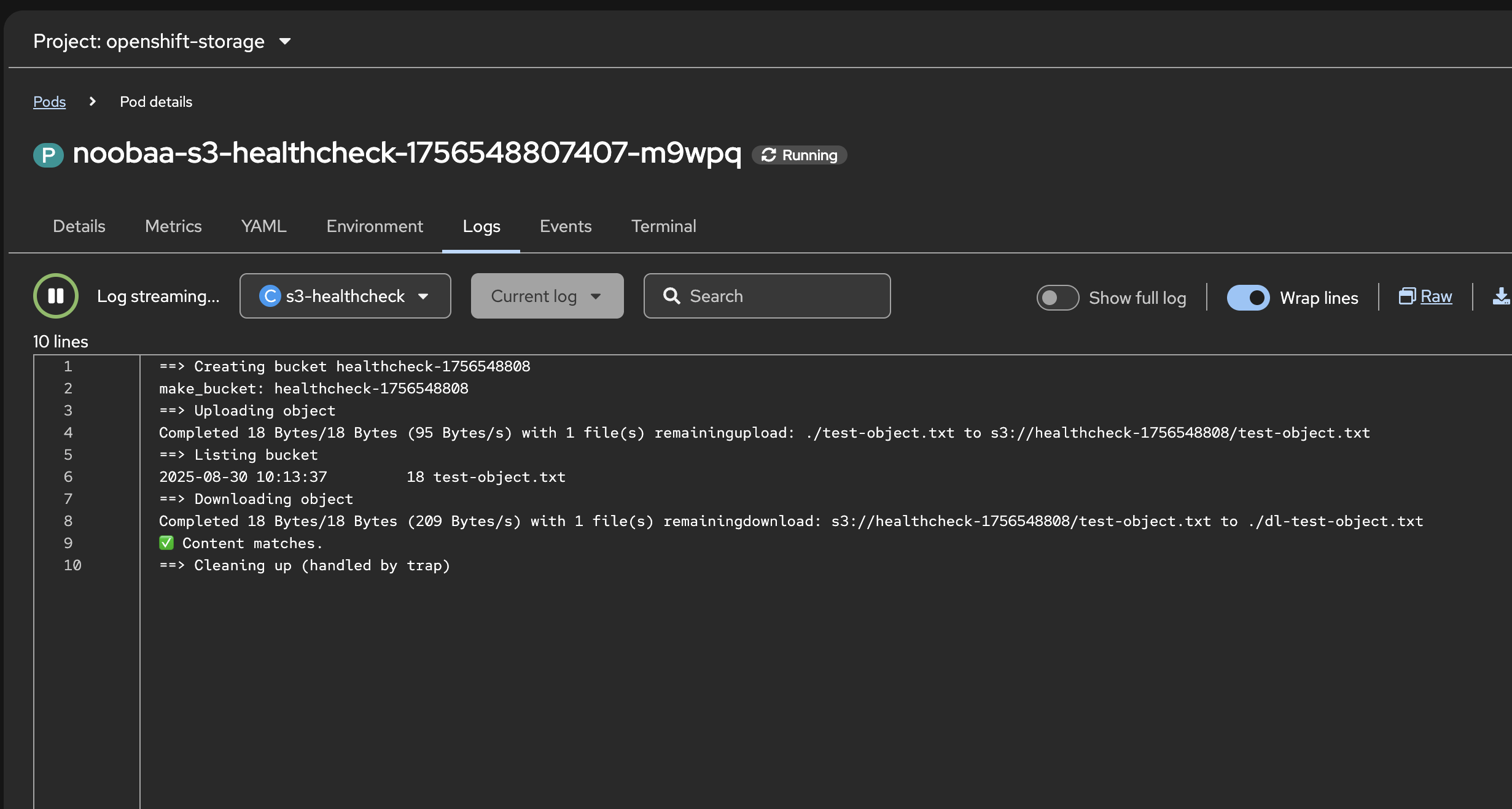
nooba-s3-health-cronjob.ymlFull Script: noobaa-s3-health-cronjob.yml
#
# noobaa-s3-health-cronjob.yml - Show Ceph OSD utilization mapped to ODF deviceset PVCs on OpenShift
#
# This manifest deploys a periodic S3 health check for NooBaa/ODF by creating a bucket, uploading/downloading an object, verifying content, and cleaning up.
#
apiVersion: v1
kind: Secret
metadata:
name: noobaa-s3-aws-creds
type: Opaque
stringData:
aws_access_key_id: "<PUT_AWS_ACCESS_KEY_ID_HERE>"
aws_secret_access_key: "<PUT_AWS_SECRET_ACCESS_KEY_HERE>"
---
apiVersion: v1
kind: ConfigMap
metadata:
name: noobaa-s3-health-script
data:
s3-client.sh: |
#!/bin/sh
set -eu
: "${AWS_ACCESS_KEY_ID:?missing}"
: "${AWS_SECRET_ACCESS_KEY:?missing}"
ENDPOINT="${ENDPOINT:-https://s3.openshift-storage.svc:443}"
export AWS_CA_BUNDLE="${AWS_CA_BUNDLE:-/etc/pki/service/ca-bundle/service-ca.crt}"
WORKDIR="${WORKDIR:-/work}"
mkdir -p "$WORKDIR"
BUCKET="healthcheck-$(date +%s)"
OBJ="$WORKDIR/test-object.txt"
DLOBJ="$WORKDIR/dl-test-object.txt"
cleanup() {
aws --endpoint-url "$ENDPOINT" s3 rm "s3://$BUCKET/$(basename "$OBJ")" >/dev/null 2>&1 || true
aws --endpoint-url "$ENDPOINT" s3 rb "s3://$BUCKET" --force >/dev/null 2>&1 || true
rm -f "$OBJ" "$DLOBJ" 2>/dev/null || true
}
trap cleanup EXIT
echo "==> Creating bucket $BUCKET"
aws --endpoint-url "$ENDPOINT" s3 mb "s3://$BUCKET"
echo "==> Uploading object"
echo "hello from noobaa" > "$OBJ"
aws --endpoint-url "$ENDPOINT" s3 cp "$OBJ" "s3://$BUCKET/"
echo "==> Listing bucket"
aws --endpoint-url "$ENDPOINT" s3 ls "s3://$BUCKET/"
echo "==> Downloading object"
aws --endpoint-url "$ENDPOINT" s3 cp "s3://$BUCKET/$(basename "$OBJ")" "$DLOBJ"
if cmp -s "$OBJ" "$DLOBJ"; then
echo "✅ Content matches."
else
echo "❌ Content mismatch!" >&2
exit 2
fi
echo "==> Cleaning up (handled by trap)"
---
apiVersion: v1
kind: ConfigMap
metadata:
name: noobaa-s3-service-ca
annotations:
service.beta.openshift.io/inject-cabundle: "true"
data: {}
---
apiVersion: batch/v1
kind: CronJob
metadata:
name: noobaa-s3-healthcheck
spec:
schedule: "*/15 * * * *"
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 3
jobTemplate:
spec:
template:
spec:
restartPolicy: Never
containers:
- name: s3-healthcheck
image: public.ecr.aws/aws-cli/aws-cli:2.18.14
imagePullPolicy: IfNotPresent
env:
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: noobaa-s3-aws-creds
key: aws_access_key_id
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: noobaa-s3-aws-creds
key: aws_secret_access_key
- name: ENDPOINT
value: "https://s3.openshift-storage.svc:443"
- name: AWS_CA_BUNDLE
value: "/etc/pki/service/ca-bundle/service-ca.crt"
- name: WORKDIR
value: "/work"
command: ["/bin/sh","-lc"]
args: ["/opt/health/s3-client.sh"]
workingDir: /work
volumeMounts:
- name: script
mountPath: /opt/health
readOnly: true
- name: service-ca
mountPath: /etc/pki/service/ca-bundle
readOnly: true
- name: workdir
mountPath: /work
resources:
requests:
cpu: 20m
memory: 64Mi
limits:
cpu: 200m
memory: 256Mi
volumes:
- name: script
configMap:
name: noobaa-s3-health-script
defaultMode: 0755
- name: service-ca
configMap:
name: noobaa-s3-service-ca
- name: workdir
emptyDir: {}TIP: If you want to change the s3 target from nooba to ceph-rgw, replace the endpoint url to
rook-ceph-rgw-ocs-storagecluster-cephobjectstore.openshift-storage.svc:443