
“Bad timekeeping is like bad DNS — nothing works right, and it’s always the last thing you check.”
Why NTP Matters in Virtualization
When you run a Proxmox node — or any virtualization stack — time synchronization isn’t just “nice to have.” It’s critical for:
- Cluster consistency: HA, Ceph, quorum votes all depend on accurate clocks.
- Certificates: SSL/TLS breaks if the system time is off.
- Logs & troubleshooting: Event correlation across nodes is impossible without sync.
- VM guests: Your VMs inherit clock drift if the host is wrong.
Yet many admins still rely on random pool.ntp.org servers and never harden their setup. The result? Logs full of falseticker warnings, clock drift, or worse — cluster instability.
The Problem with Public Pools
If you’re running Proxmox, you might see logs like:
chronyd[957]: Detected falseticker pool.ntp.org
chronyd[957]: Can't synchronise: no majority
chronyd[957]: System clock wrong by 1.1 secondsThat’s your NTP client (Chrony) saying:
“I asked several public servers what time it is. They don’t agree, and I don’t trust any of them.”
Public pools are great for desktops — but for a hypervisor or a cluster, they’re too unpredictable.
Step 1: Harden Your Chrony Configuration
Edit /etc/chrony/chrony.conf and swap out the weak defaults for stable, Anycast-backed services and regional pools:
# =====================================================================
# Chrony hardened config for Proxmox (Singapore / Asia region)
# =====================================================================
# Cloudflare NTP (Anycast, fast + secure)
server time.cloudflare.com iburst prefer
# Google Public NTP
server time.google.com iburst
# Singapore pool (regional NTP)
server 0.sg.pool.ntp.org iburst
server 1.sg.pool.ntp.org iburst
server 2.sg.pool.ntp.org iburst
server 3.sg.pool.ntp.org iburst
# ---------------------------------------------------------------------
# SECURITY SETTINGS
# ---------------------------------------------------------------------
# Don't serve NTP to others (local node only)
port 0
# Allow only localhost to control chronyd
cmdallow 127.0.0.1
cmdallow ::1
# Don’t accept external remote commands
cmdport 0
# ---------------------------------------------------------------------
# RELIABILITY
# ---------------------------------------------------------------------
# Step the system clock if the adjustment is bigger than 1 sec
makestep 1.0 3
# Record drift for stability
driftfile /var/lib/chrony/chrony.drift
# Log files
logdir /var/log/chrony
log measurements statistics tracking
Restart Chrony & check status:
systemctl restart chronyd
sleep 15
chronyc sources -v
chronyc tracking
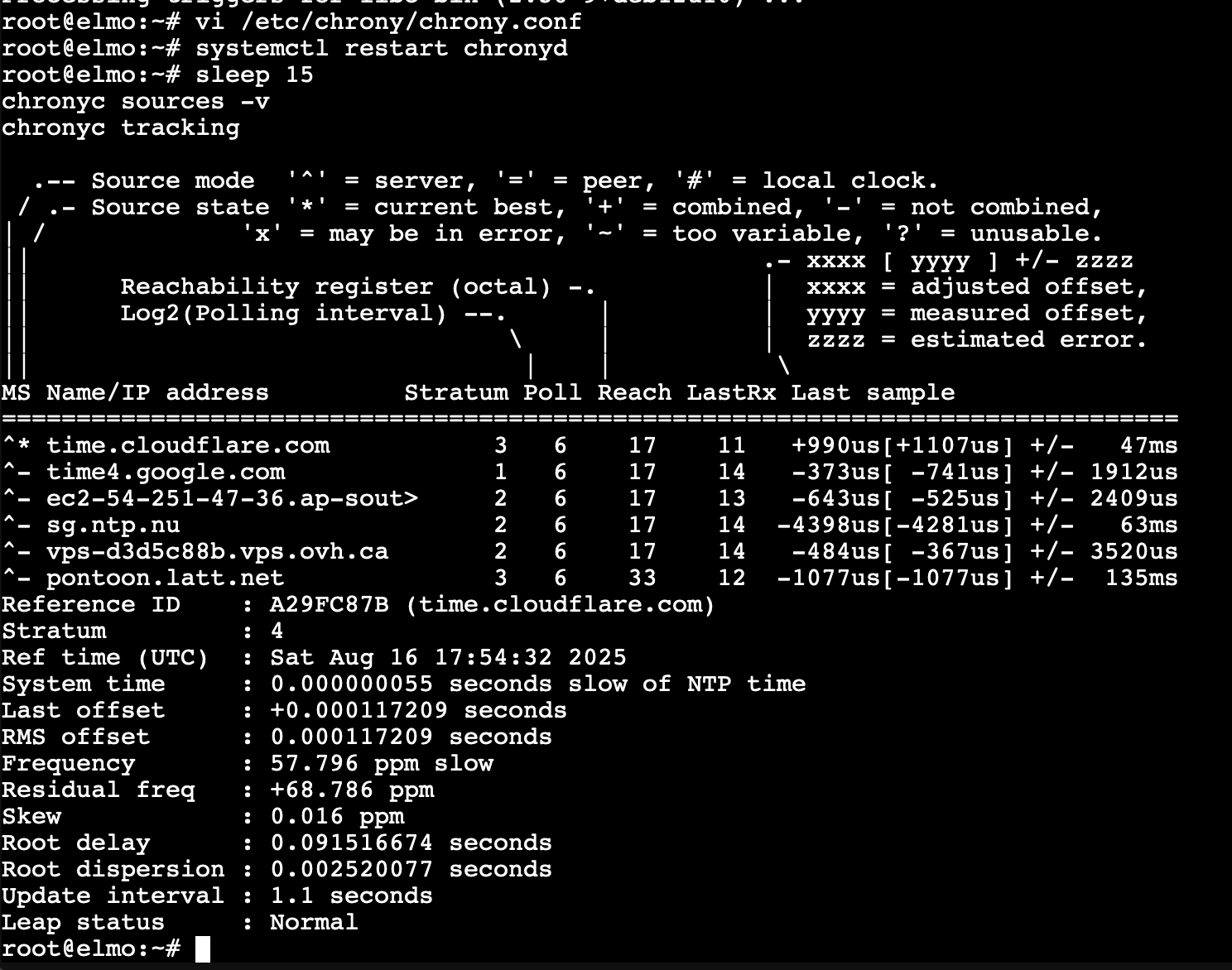
You want to see a ^* marking your chosen server and a Leap status: Normal.
^*= primary source (Cloudflare in this case)Reach 377= excellent (8/8 last polls succeeded)Last offset= small drift (good sign)Leap statusshould change toNormal- Stratum <= 4 is fine.
Step 2: Run Your Own NTP Server
Public services are better than nothing, but the real fix is to be your own source of truth:
- Single node? Run Chrony normally, pointed at Cloudflare/Google.
- Multiple Proxmox nodes? Pick one node as your “stratum 1” and point the others at it.
- Enterprise / homelab with pfSense, OPNsense, MikroTik, etc.? Let your router/firewall act as the LAN’s NTP server.
That way:
- All nodes agree with each other, even if WAN is flaky.
- You reduce dependency on random Internet servers.
- Logs and metrics are perfectly aligned across your infrastructure.
Step 3: Don’t Forget the Firewall
Chrony uses UDP/123. If you’re running Proxmox VE Firewall, allow outbound NTP or you’ll stay stuck at Leap status: Not synchronised.
Example (pve-firewall rule):
OUT ACCEPT udp dport 123The Bottom Line
- Accurate time isn’t optional in virtualization — it’s foundational.
- Don’t trust only public pools. Harden your Chrony config with stable providers.
- Even better: run your own NTP server and let your nodes sync internally.
Your future self — staring at weird cluster errors at 3 AM — will thank you.