
In OpenShift, MachineConfigPool (MCP) updates are not “just config changes.” They trigger node reboots when anything in the MachineConfig changes that affects RHCOS’ immutable OS layer.
Why control the blast radius
1. Avoid mass pod disruption
- If you have a single MCP for all workers, every worker will reboot, draining and rescheduling workloads.
- In clusters with tight capacity, pods may not have room to reschedule → degraded apps, outages.
- Masters reboot too (for their own MCP), temporarily reducing control-plane quorum while each restarts.
2. Avoid quorum loss on the control plane
- Masters are in their own MCP (master).
- If you reboot too many at once (or don’t wait for one to fully come back), etcd quorum can be lost → full API outage.
- The MCO is cautious with masters (one-at-a-time), but if you also change the worker pool at the same time, you stress the cluster twice over.
3. Avoid parallel drain storms
- On large clusters, multiple MCPs can roll in parallel unless you pause them.
- Each draining node will evict workloads → if your PodDisruptionBudgets are tight, updates can fail or leave workloads unavailable.
Why pause MCP (masters vs workers)
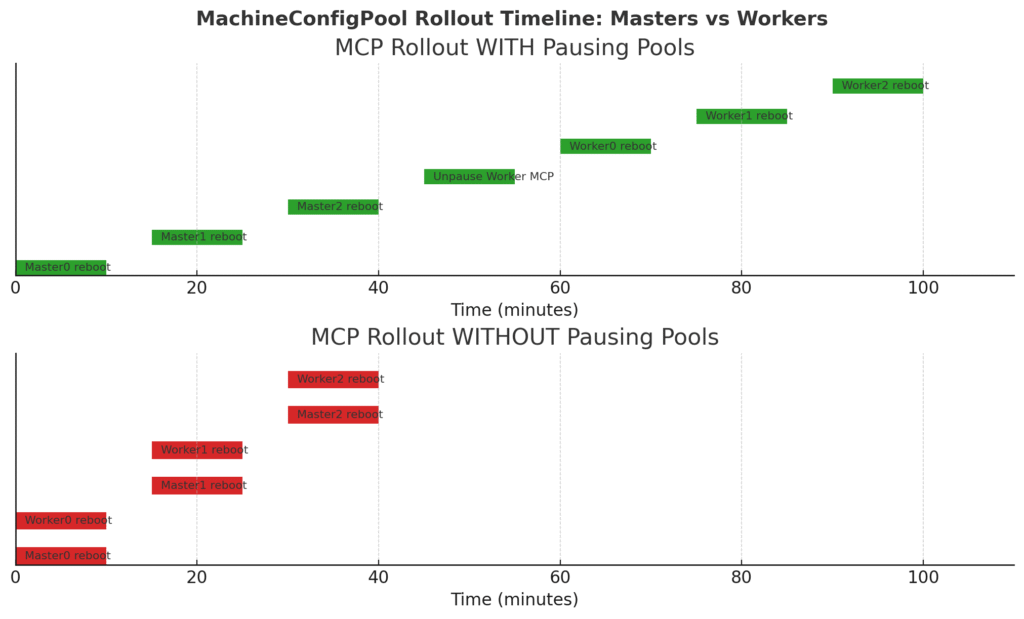
Top (green) — With pausing:
- Masters roll one at a time (0 → 15 → 30 min).
- Only after masters are done, workers roll one at a time after unpausing (45 min onward).
- Minimal disruption overlap.
Bottom (red) — Without pausing:
- Masters and workers start rolling at the same time.
- Multiple drains happen in parallel, more pod evictions, higher disruption risk, and more stress on scheduling capacity.
This is why pausing MCPs before a big config change keeps the blast radius under control.
How to control it?
Pause the MCP, apply your mirror objects, then unpause during a window (Do masters separately):
oc patch mcp worker -p '{"spec":{"paused":true}}' --type=mergeOnce it’s paused (check mcp to make sure the changes above is applied), then apply the change → unpause the pool you want to roll → wait until it’s fully updated → then unpause the next pool.
oc patch mcp worker -p '{"spec":{"paused":false}}' --type=merge- Do masters first if the change affects both pools, so control-plane is stable before you touch the workers.
- Use canary MCPs for big fleets — assign a subset of nodes to a separate MCP (label selectors) and let that roll first.
If you only need a one‑off image fixed fast, you can override references in that deployment to point straight at your mirror and avoid a global node reboot.
Expect any pods that were in ImagePullBackOff to restart anyway once mirrors are active—they’ll finally pull and come up.