
I noticed the last script did not cater for the scenario that the node is an SNO. What happened to my SNO was that many pods were not scheduled and I lost access to the console and api. The only way I could recover it was to get into the SNO via SSH, and uncordon the node using the kubeconfig stored within.
In this case, I’ve done an upgrade to the script. Enjoy the script!
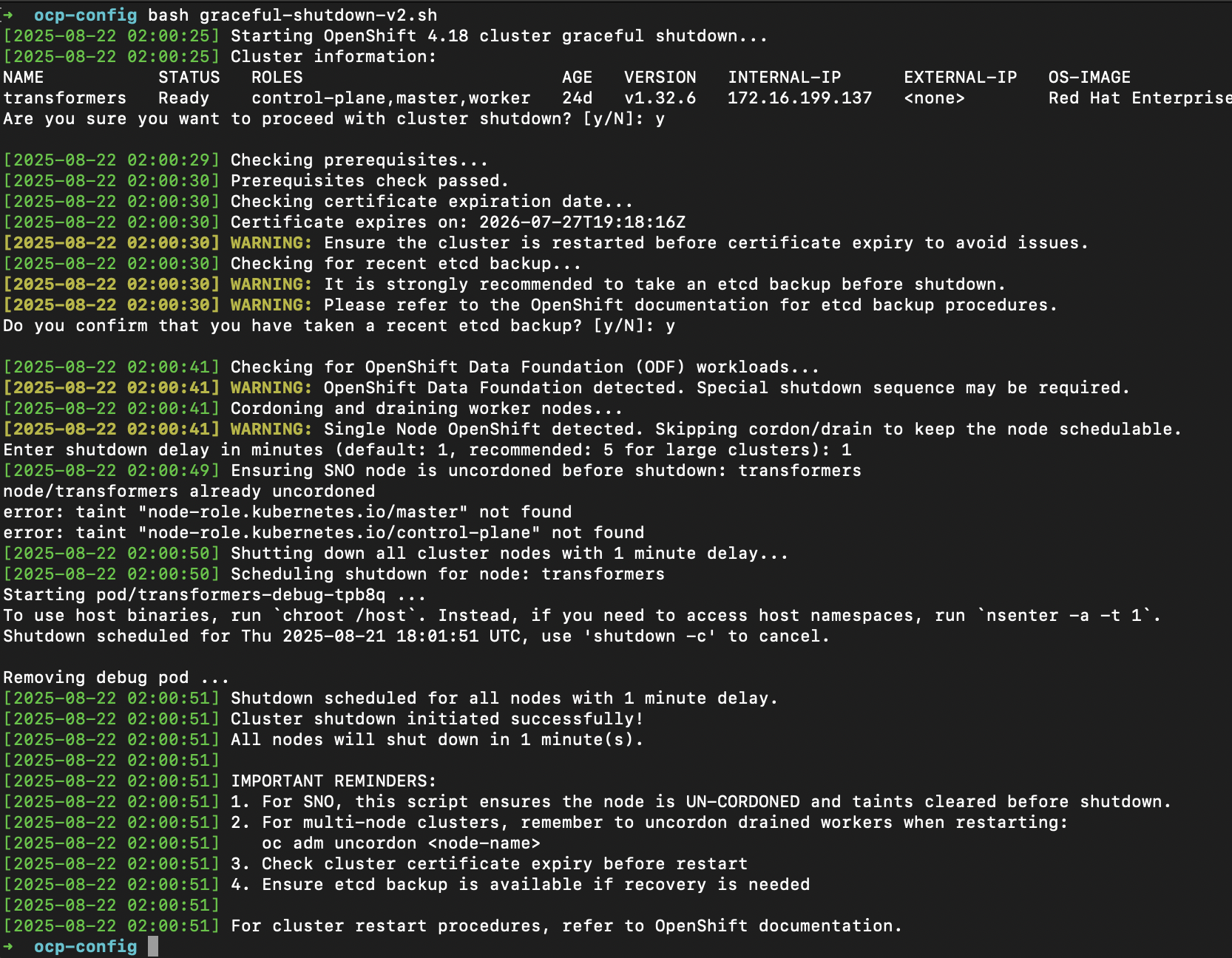
Script
#!/bin/bash
# OpenShift 4.18 Graceful Shutdown Script for Air-gapped Environment
# Compatible with RHEL 9.6
# Script to gracefully shutdown OpenShift cluster
# SNO-safe: skips cordon/drain on Single Node OpenShift and ensures node is uncordoned before shutdown
set -euo pipefail
# Color codes for output
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
NC='\033[0m' # No Color
# Logging functions
log() { echo -e "${GREEN}[$(date '+%Y-%m-%d %H:%M:%S')]${NC} $1"; }
warn() { echo -e "${YELLOW}[$(date '+%Y-%m-%d %H:%M:%S')] WARNING:${NC} $1"; }
error() { echo -e "${RED}[$(date '+%Y-%m-%d %H:%M:%S')] ERROR:${NC} $1"; exit 1; }
# Confirmation prompt
confirm() {
read -p "$1 [y/N]: " -r
echo
[[ ${REPLY:-} =~ ^[Yy]$ ]]
}
# Detect Single Node OpenShift
is_sno() {
local count
count="$(oc get nodes --no-headers 2>/dev/null | wc -l | tr -d ' ')"
[[ "$count" -eq 1 ]]
}
# Check prerequisites
check_prerequisites() {
log "Checking prerequisites..."
# Check if oc command is available
if ! command -v oc &> /dev/null; then
error "OpenShift CLI (oc) not found. Please install and configure oc command."
fi
# jq used for JSON processing when present (optional but recommended)
if ! command -v jq &> /dev/null; then
warn "jq not found. Some advanced filtering will be skipped."
fi
# Check if we have cluster-admin access
if ! oc auth can-i '*' '*' --all-namespaces &> /dev/null; then
error "You need cluster-admin privileges to run this script."
fi
# Check if cluster is accessible
if ! oc get nodes &> /dev/null; then
error "Cannot access the cluster. Please check your connection and authentication."
fi
log "Prerequisites check passed."
}
# Check certificate expiration
check_certificate_expiry() {
log "Checking certificate expiration date..."
cert_expiry="$(oc -n openshift-kube-apiserver-operator get secret kube-apiserver-to-kubelet-signer \
-o jsonpath='{.metadata.annotations.auth\.openshift\.io/certificate-not-after}' 2>/dev/null || echo "")"
if [[ -n "$cert_expiry" ]]; then
log "Certificate expires on: $cert_expiry"
warn "Ensure the cluster is restarted before certificate expiry to avoid issues."
else
warn "Could not retrieve certificate expiry information."
fi
}
# Take etcd backup (confirmation gate)
take_etcd_backup() {
log "Checking for recent etcd backup..."
warn "It is strongly recommended to take an etcd backup before shutdown."
warn "Please refer to the OpenShift documentation for etcd backup procedures."
if ! confirm "Do you confirm that you have taken a recent etcd backup?"; then
error "Please take an etcd backup before proceeding with cluster shutdown."
fi
}
# Cordoning and draining worker nodes (SNO-safe)
drain_worker_nodes() {
log "Cordoning and draining worker nodes..."
if is_sno; then
warn "Single Node OpenShift detected. Skipping cordon/drain to keep the node schedulable."
return 0
fi
# Get nodes labeled as worker
worker_nodes="$(oc get nodes -l node-role.kubernetes.io/worker -o jsonpath='{.items[*].metadata.name}' 2>/dev/null || echo "")"
if [[ -z "$worker_nodes" ]]; then
warn "No dedicated worker nodes found. This might be a compact cluster. Skipping drain."
return 0
fi
# Exclude nodes that are also control-plane/master if jq is available
filtered_workers=""
if command -v jq &>/dev/null; then
for n in $worker_nodes; do
if ! oc get node "$n" -o json \
| jq -e '.metadata.labels["node-role.kubernetes.io/master"] or .metadata.labels["node-role.kubernetes.io/control-plane"]' >/dev/null; then
filtered_workers+="$n "
fi
done
else
# Fallback without jq (best effort): leave list as-is
filtered_workers="$worker_nodes"
fi
if [[ -z "$filtered_workers" ]]; then
warn "No dedicated workers after filtering; skipping drain."
return 0
fi
# Cordon all filtered workers
for node in $filtered_workers; do
log "Cordoning node: $node"
oc adm cordon "$node" || warn "Failed to cordon $node"
done
# Drain all filtered workers
for node in $filtered_workers; do
log "Draining node: $node"
oc adm drain "$node" --delete-emptydir-data --ignore-daemonsets=true --timeout=15s --force \
|| warn "Failed to drain $node completely"
done
log "Dedicated worker nodes cordoned and drained."
}
# Handle special workloads (if ODF/Ceph is present)
handle_special_workloads() {
log "Checking for OpenShift Data Foundation (ODF) workloads..."
if oc get namespace openshift-storage &>/dev/null; then
warn "OpenShift Data Foundation detected. Special shutdown sequence may be required."
if command -v jq &>/dev/null; then
odf_pvcs="$(oc get pvc -A -o json \
| jq -r '.items[] | select(.spec.storageClassName // "" | test("ocs-storagecluster-ceph")) | .metadata.namespace + "/" + .metadata.name' 2>/dev/null || echo "")"
if [[ -n "$odf_pvcs" ]]; then
log "Found workloads using ODF storage. Shutting down pods using ODF storage..."
while IFS= read -r pvc; do
ns="${pvc%%/*}"
claim="${pvc##*/}"
pods="$(oc get pods -n "$ns" -o json \
| jq -r --arg claim "$claim" '.items[] | select(.spec.volumes[]? | select(.persistentVolumeClaim.claimName == $claim)) | .metadata.name' 2>/dev/null || echo "")"
for pod in $pods; do
log "Deleting pod $pod in namespace $ns (using ODF storage)"
oc delete pod "$pod" -n "$ns" --grace-period=30 || warn "Failed to delete pod $pod"
done
done <<< "$odf_pvcs"
fi
else
warn "jq not available; skipping fine-grained ODF PVC/pod cleanup."
fi
fi
}
# Ensure SNO node is schedulable (uncordon + clear taints)
ensure_sno_schedulable() {
if is_sno; then
NODE="$(oc get node -o jsonpath='{.items[0].metadata.name}')"
log "Ensuring SNO node is uncordoned before shutdown: $NODE"
oc adm uncordon "$NODE" || warn "Failed to uncordon SNO node $NODE"
# Clear common control-plane NoSchedule taints if present
oc adm taint nodes "$NODE" node-role.kubernetes.io/master- || true
oc adm taint nodes "$NODE" node-role.kubernetes.io/control-plane- || true
fi
}
# Shutdown cluster nodes
shutdown_nodes() {
local shutdown_delay="${1:-1}"
log "Shutting down all cluster nodes with ${shutdown_delay} minute delay..."
all_nodes="$(oc get nodes -o jsonpath='{.items[*].metadata.name}')"
if [[ -z "$all_nodes" ]]; then
error "No nodes found in the cluster."
fi
node_count="$(echo "$all_nodes" | wc -w)"
if [[ $node_count -ge 10 ]] && [[ $shutdown_delay -eq 1 ]]; then
shutdown_delay=10
warn "Large cluster detected ($node_count nodes). Using ${shutdown_delay} minute shutdown delay."
fi
for node in $all_nodes; do
log "Scheduling shutdown for node: $node"
oc debug node/"$node" -- chroot /host shutdown -h "$shutdown_delay" || warn "Failed to schedule shutdown for $node"
done
log "Shutdown scheduled for all nodes with ${shutdown_delay} minute delay."
}
# Main shutdown function
main() {
log "Starting OpenShift 4.18 cluster graceful shutdown..."
log "Cluster information:"
oc get nodes -o wide | head -10
# Final confirmation
if ! confirm "Are you sure you want to proceed with cluster shutdown?"; then
log "Shutdown cancelled by user."
exit 0
fi
# Execute shutdown steps
check_prerequisites
check_certificate_expiry
take_etcd_backup
handle_special_workloads
drain_worker_nodes
# Ask for custom shutdown delay
read -p "Enter shutdown delay in minutes (default: 1, recommended: 5 for large clusters): " -r custom_delay || true
delay="${custom_delay:-1}"
# Validate delay is a number
if ! [[ "$delay" =~ ^[0-9]+$ ]]; then
warn "Invalid delay specified. Using default delay of 1 minute."
delay=1
fi
# Safety net for SNO: ensure node is schedulable before power-off
ensure_sno_schedulable
shutdown_nodes "$delay"
log "Cluster shutdown initiated successfully!"
log "All nodes will shut down in $delay minute(s)."
log ""
log "IMPORTANT REMINDERS:"
log "1. For SNO, this script ensures the node is UN-CORDONED and taints cleared before shutdown."
log "2. For multi-node clusters, remember to uncordon drained workers when restarting:"
log " oc adm uncordon <node-name>"
log "3. Check cluster certificate expiry before restart"
log "4. Ensure etcd backup is available if recovery is needed"
log ""
log "For cluster restart procedures, refer to OpenShift documentation."
}
# Execute main function
main "$@"